
Project
Vision
The Intellexus Project strives to revolutionise the study of Indic and Tibetic Buddhist intellectual cultures, by combining the hitherto well-tried historical-philological methods and the history of ideas perspective with cutting-edge computational tools and techniques and a new theoretical approach of intellectual ecosystems.
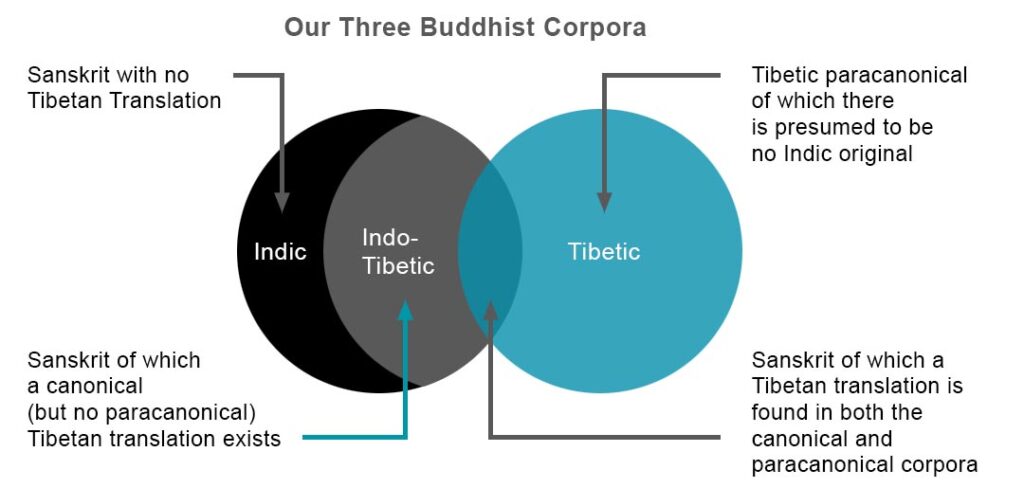
The project aims at mapping three large corpora of mainly Buddhist texts: Indic, Indo-Tibetic, and Tibetic, so as to make it possible to understand how these corpora evolved and how the respective intellectual cultures developed and thrived as complex dynamic systems. With a flood of texts in Sanskrit and Tibetan becoming available, the philological approach needs urgently to be supplemented, updated, and revised, especially in the light of developments in Artificial Intelligence and Natural Language Processing. Taking on this challenge, Intellexus will develop innovative methods for investigating the interdependent evolution of the three corpora and sophisticated visualisations of the intricate interactions, within and across cultural, linguistic, and religious boundaries. More broadly, the project also strives to provide a model that can transform the study of other intellectual cultures and have impact on other domains of interest.
Team

Intellexus involves two main research groups. A humanistic group, which is based at the University of Hamburg (UHH), consists of philologists focusing on textual material from one (or more) of the three corpora under investigation and covering a range of genres and topics that serve as case studies for the development of the computational tools. The group comprises three sub-teams, each focusing on material from one of the three corpora under investigations. The computer-scientific group, which is based at Reichman University (RUNI), comprises two sub-teams, including a research team, focusing on language modelling and algorithm development, and a technology and development team, focusing on the empirical work, software development of the technology, and support and management of the compute environment.
Synergy
Intellexus focuses on eight domains of expertise: four domains concerning a linguistic aspect, including (a) Sanskrit, (b) Canonical Tibetan, (c) Paracanonical Tibetan, and (d) Natural Language Processing (NLP), and four domains concerning thematic aspects, including
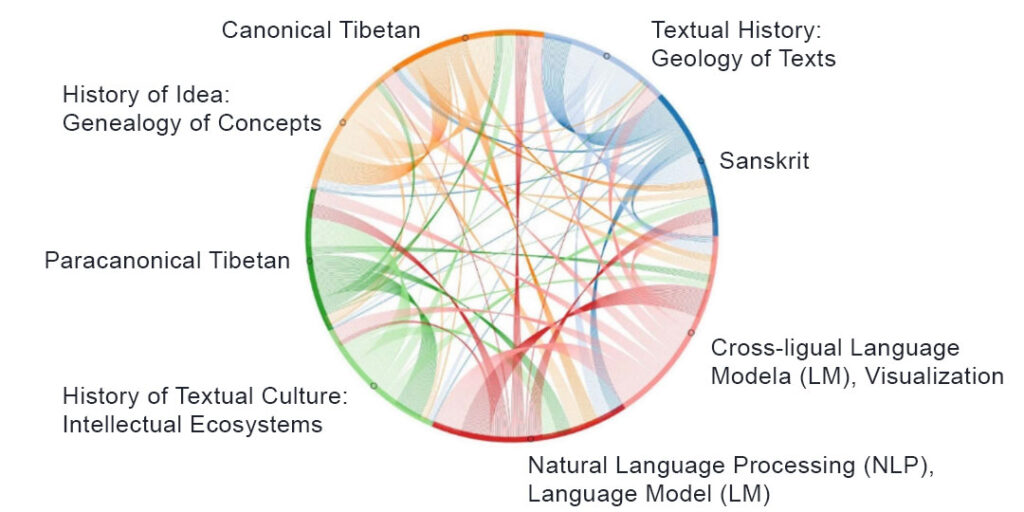
(a) Textual History (Geology of Texts), (b) History of Ideas (Genealogy of Concepts), (c) History of Textual Culture (Intellectual Ecosystems), and (d) Language Models (LM), Cross-lingual Language Models (LM), and Visualizations. To ensure a high degree of synergy, Intellexus follows an approach in which it is guaranteed that all of the eight domains interact with each other, to varying degree and intensity as required at any given phase of the project.
Plan
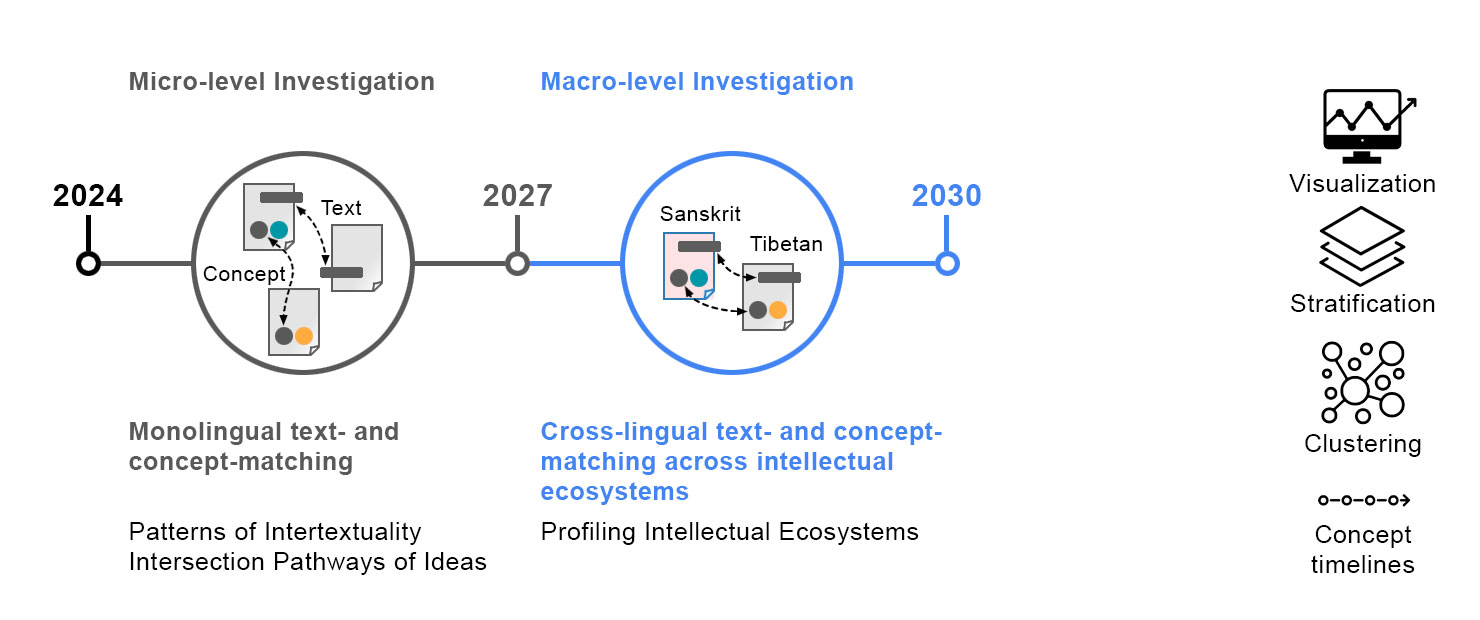
Intellexus has two main parts, micro- and macro-level, each covering three years. The micro-level focuses primarily on individual texts, concepts, and elements of the intellectual ecosystems, and aims to develop monolingual computational tools and methods for Sanskrit and Tibetan. This level also involves historical-philological groundwork for texts selected as case studies, and investigations of the overarching topics “Patterns of Intertextuality” and “Intersecting Pathways of Ideas.” In the macro-level we zoom out in focus to develop methods that can be applied cross-lingually and across the corpora and the entire intellectual ecosystems. These include clustering, stratification, cross-lingual matching of texts and concepts, and visualisations. On this level, we will apply the developed tools and methods to the case studies, and investigate the overarching topic “Profiling Intellectual Ecosystems.”
Example 1: Origins and Evolution of Treasure Literature
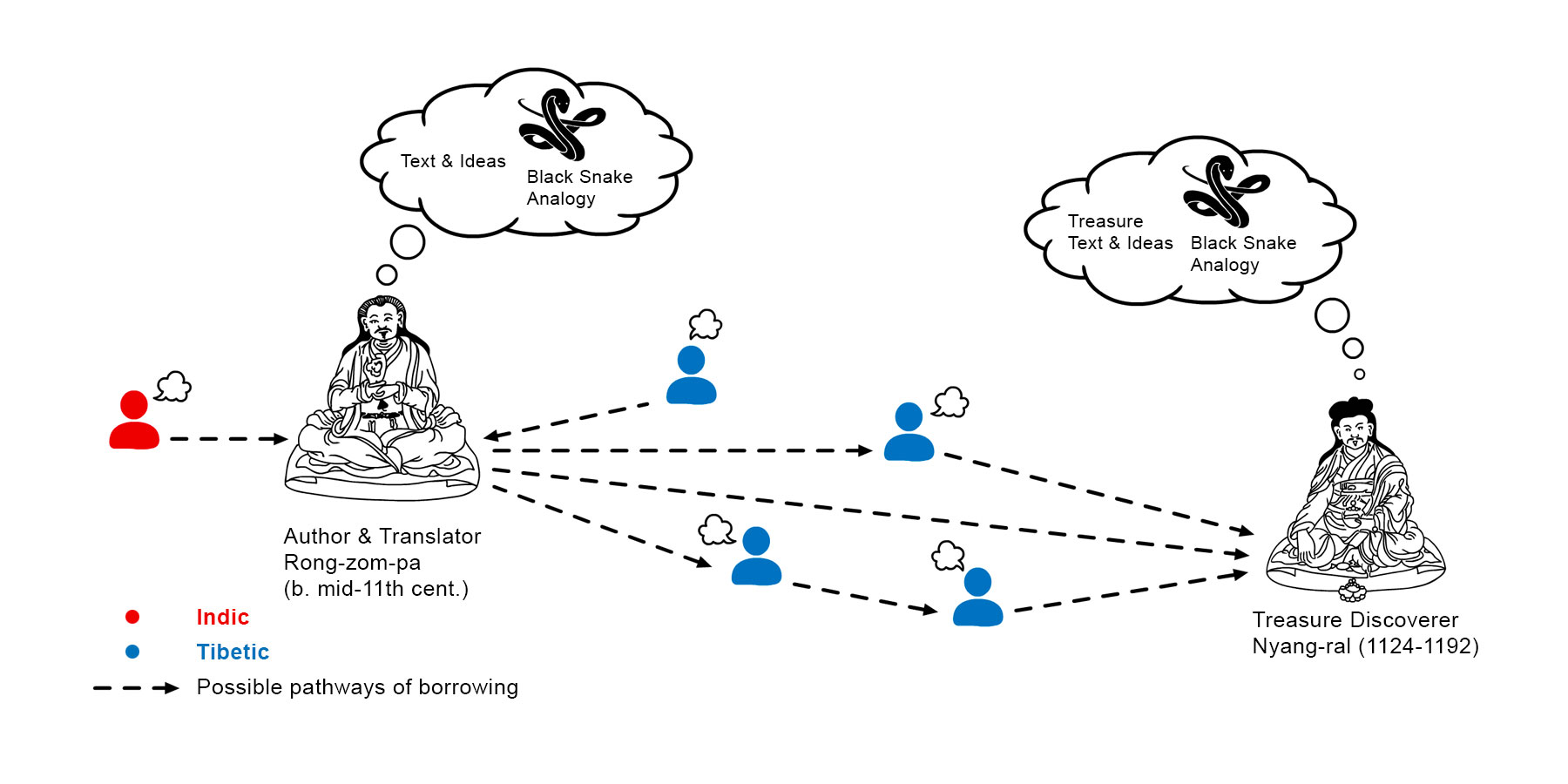
One question that Intellexus investigates is the origins and evolution of the vast Tibetan treasure literature, which are still shrouded in mystery. This is true also for the history of the ideas contained in them and the intellectual ecosystems behind their creation. For instance, the analogy of an optical illusion of a black snake, used by the 11th-century Tibetan scholar Rong-zom-pa to illustrate different ontologies and the corresponding soteriologies according to five Buddhist philosophical systems, is usually regarded as his original conception. Now, it appears in almost the same words in a discovered treasure of the 12th-century Tibetan Treasure Revealer Nyang-ral. Intellexus strives to offer answers to questions such as: Through which channels did this analogy reach Nyang-ral? Was there any connection between the intellectual circles of Rong-zom-pa and Nyang-ral? Or perhaps Rong-zom-pa himself borrow the idea at least from earlier sources? If so, along what intellectual networks did it travel in India, from India to Tibet, and in Tibet; what has been added to it, and why? The investigation of the origins and evolution of the Tibetan treasure literature will mainly leverage the capability of tracing monolingual concepts over time.
Example 2: Origins and Evolution of Buddhist Tantric Scriptures
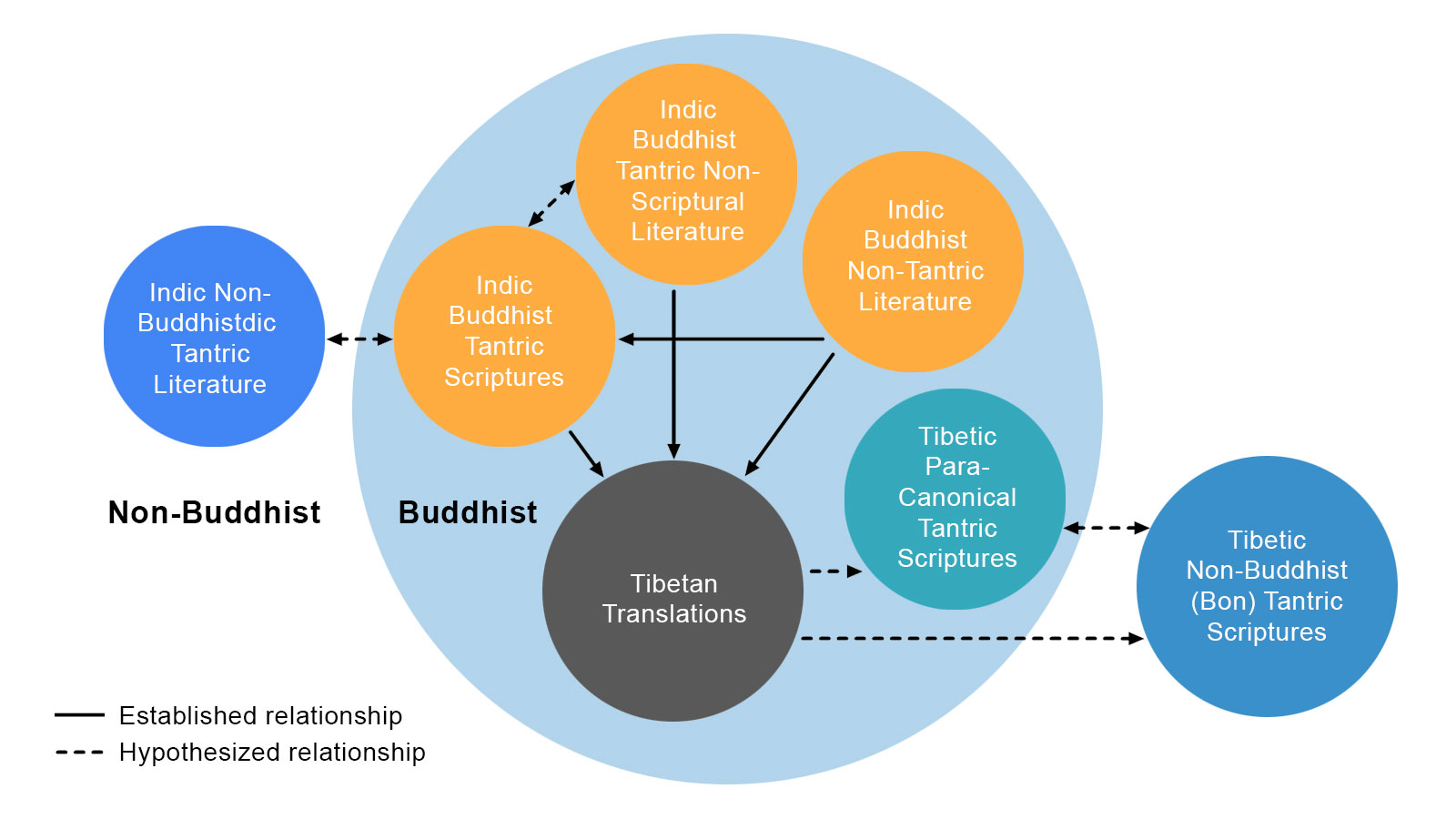
An even larger question that Intellexus tackles is that of the development of Buddhist Tantric scriptures, which form a large part within each of our three corpora. This also involves the problem of the exact nature of the relationship between Buddhist and non-Buddhist Tantric forms of religion, both in India and Tibet. These matters have been studied so far on the basis of only a very tiny fraction of the vast material. One or two non-Tantric sources have been pinpointed, and a few examples have been identified of probable borrowing from non-Buddhist Tantric scriptures, though these are somewhat controversial. The development of Buddhist Tantric scriptures will mainly leverage cross-lingual concept matching.
The Intellexus Platform:
text and people
Intellexus will develop a platform that comprises texts in Sanskrit and Tibetan, metadata related to them, and sophisticated visualisation options, which will open new ways to understanding the development and evolution of Indic and Tibetic Buddhist intellectual cultures.

The Intellexus Platform:
ideas and concepts
The Intellexus platform will allow an identification of direct and indirect borrowing of texts and ideas on a large scale, both mono- and cross-lingually. It will also provide the means to trace the pathways along which concepts travelled and identify their intersections.
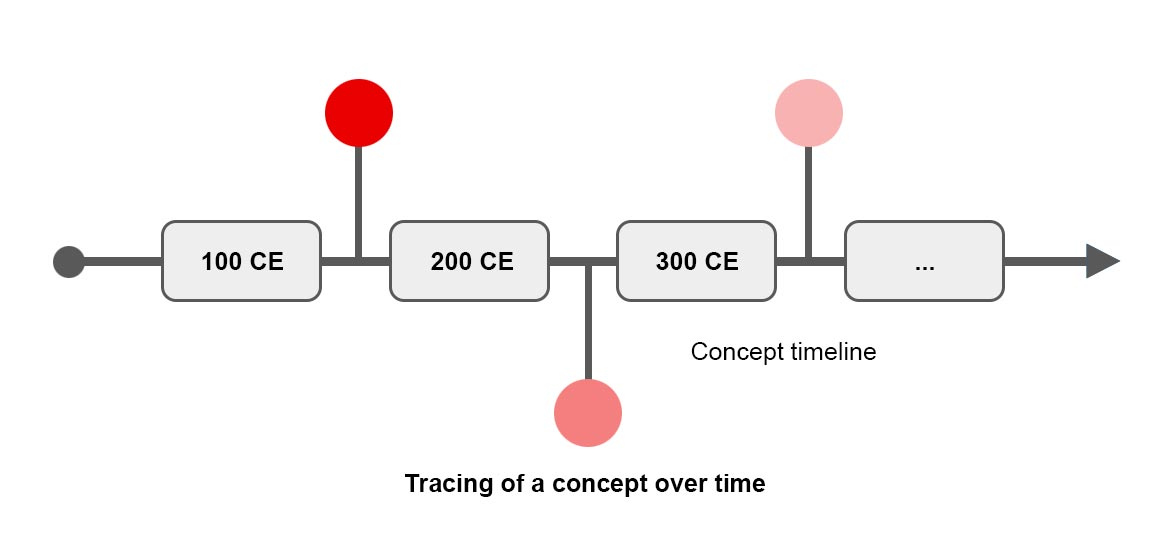
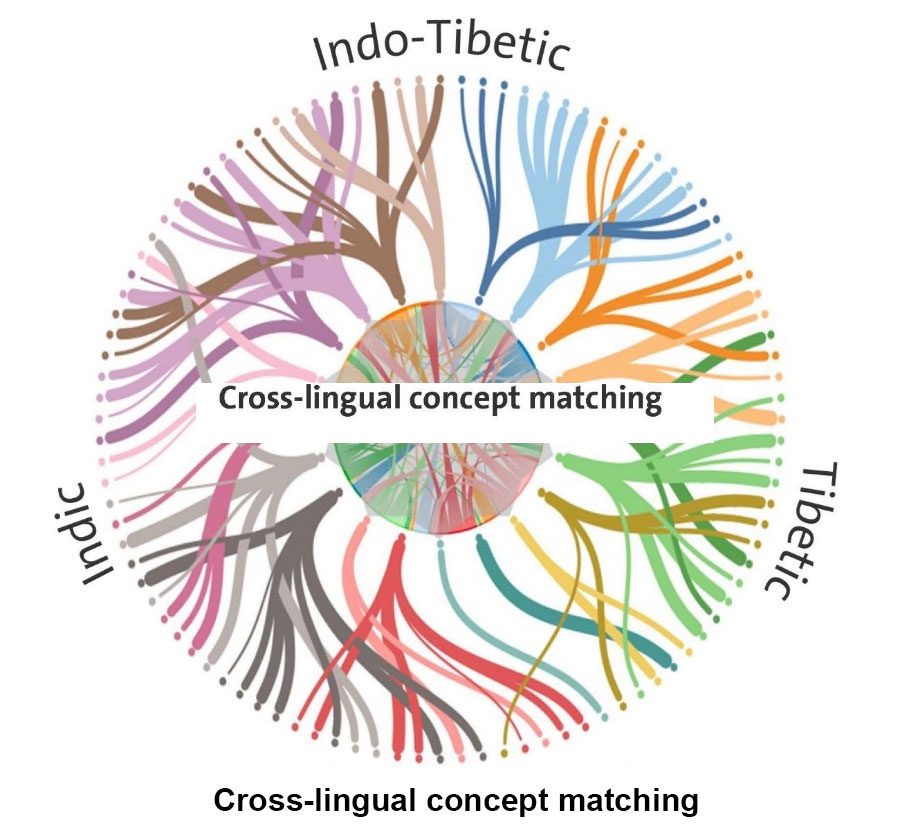
The platform will enable a large-scale mapping of the Indic and Tibetic texts, the idea contained therein, and the intellectual ecosystems behind them. At the same time it will also facilitate individual research projects focusing on selected texts, in offering answers to complex questions concerning textual history, history of ideas, and history of textual culture.